
Face recognition technology is advancing at a rapid pace. From unlocking smartphones to streamlining airport security, it’s now embedded in everyday life. But building robust face recognition systems requires massive amounts of diverse training data – a challenge due to privacy laws, data scarcity, and bias.
That’s where synthetic datasets come in. These computer-generated datasets for ML models simulate real human faces at scale, giving researchers and engineers a powerful alternative to collecting sensitive real-world images. Synthetic data is changing not only how face recognition systems are trained but also how they perform in real-world conditions.
In this article, we’ll explore why synthetic datasets matter, how they compare to traditional data, and what the future looks like for face recognition powered by synthetic data.
Why Traditional Face Recognition Datasets Fall Short
Traditional datasets for face recognition rely on photographs of real people. While useful, they introduce several problems:
- Privacy concerns: Collecting and storing biometric data raises serious ethical and legal issues.
- Bias and imbalance: Many datasets overrepresent certain demographics (e.g., lighter skin tones or younger faces), which leads to biased models.
- Limited scalability: Gathering millions of diverse, high-quality images is costly and slow.
- Regulation challenges: Laws like GDPR and CCPA restrict how facial data can be used.
According to a National Institute of Standards and Technology (NIST) report, face recognition systems showed 10 to 100 times higher error rates for Asian and African American faces compared to Caucasian faces (NIST Report). These biases highlight the limits of traditional datasets.
What Are Synthetic Datasets?
A synthetic dataset is artificially generated data created with tools like 3D modeling, generative adversarial networks (GANs), or simulation engines. Instead of photographing real people, researchers generate realistic yet fake images of faces that mimic the statistical properties of real data.
For example, a synthetic dataset might contain:
- Millions of unique, computer-generated faces.
- Faces with different lighting, poses, and backgrounds.
- Variations in age, gender, ethnicity, and accessories like glasses.
This approach allows for limitless scalability and avoids privacy concerns because no real person is represented.
Benefits of Synthetic Datasets for Face Recognition
Synthetic datasets bring several advantages over traditional datasets:
- Privacy-friendly: Since faces are not tied to real individuals, data protection issues are minimized.
- Bias reduction: Researchers can generate balanced datasets across age groups, genders, and skin tones.
- Scalability: Large datasets can be generated in days, not months.
- Edge-case coverage: Rare scenarios – like extreme lighting or unusual poses – can be easily simulated.
Traditional vs Synthetic Datasets for Face Recognition
Before diving deeper, it helps to compare traditional and synthetic datasets side by side. While both aim to power face recognition systems, their differences in privacy, scalability, and bias handling make them suited for very different use cases. The table below highlights the most important contrasts.
| Feature | Traditional Datasets | Synthetic Datasets |
| Data Source | Real human photos | Computer-generated faces |
| Privacy Risks | High – biometric data linked to individuals | Low – no real identities involved |
| Bias Issues | Often skewed toward certain demographics | Can be balanced by design |
| Scalability | Limited by collection costs and regulations | Virtually unlimited |
| Edge Cases | Hard to capture | Easy to simulate |
| Annotation | Manual or semi-automated | Fully automated, consistent |
This comparison makes it clear why synthetic datasets are gaining traction in face recognition research.
How Synthetic Faces Are Generated
Synthetic datasets use a mix of methods to create realistic faces:
- 3D Modeling: Software generates virtual heads with customizable features (skin tone, eye shape, age).
- GANs (Generative Adversarial Networks): Neural networks trained to produce ultra-realistic fake images, like the ones seen in “This Person Does Not Exist.”
- Simulation Engines: Tools similar to video game graphics engines create lifelike environments and faces.
- Hybrid Approaches: Combining real data with synthetic variations to improve realism.
These techniques ensure synthetic datasets capture both diversity and realism, key to training face recognition systems.
Growth of Synthetic Dataset Adoption
Understanding adoption is easier when looking at market trends. According to Grand View Research, the global synthetic data generation market was valued at approximately USD 218.4 million in 2023 and is projected to reach nearly USD 1.79 billion by 2030.
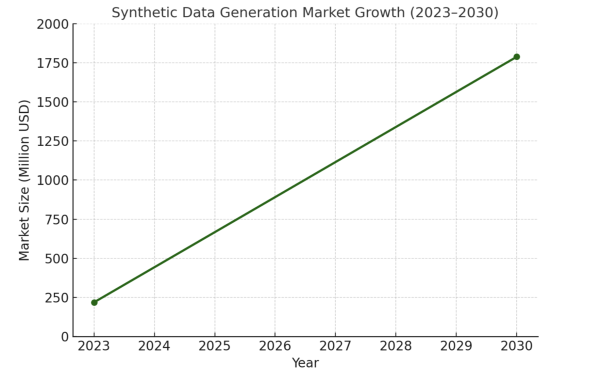
This steep growth curve reflects how industries are increasingly turning to synthetic datasets to solve challenges in privacy, data scarcity, and bias reduction. For face recognition in particular, a rapidly expanding synthetic data market means more advanced tools, better dataset diversity, and faster progress in model training.
The Lifecycle of a Synthetic Face Recognition Dataset
The lifecycle of a synthetic face recognition dataset describes the is a continuous process of generating, annotating, training, and refining artificial facial data to build robust machine learning models. It begins with data generation using techniques such as generative adversarial networks (GANs) or 3D modeling to create realistic yet privacy-safe faces. These images are then annotated with labels like facial landmarks, bounding boxes, and demographic attributes to make them suitable for supervised learning. The annotated dataset is used to train deep learning models, which are evaluated for accuracy, bias, and performance under diverse conditions. Based on evaluation results, the dataset is refined by adding new synthetic samples or adjusting distributions to address weaknesses, completing a feedback loop. This iterative cycle ensures that face recognition systems evolve with greater fairness, diversity, and robustness, while reducing reliance on sensitive real-world biometric data.

This lifecycle demonstrates why synthetic datasets are so powerful: they allow for iterative improvement at scale, something much harder to achieve with traditional datasets.
Applications of Synthetic Datasets in Face Recognition
Synthetic datasets are already making an impact across industries:
- Security and Law Enforcement – Training models for surveillance systems without exposing personal data.
- Healthcare – Improving patient recognition in hospitals while protecting identities.
- Consumer Tech – Powering facial recognition in smartphones and AR/VR devices.
- Education and Research – Allowing universities to experiment with face recognition models without legal hurdles.
For example, companies like Datagen and Synthesis AI provide synthetic datasets tailored for face recognition and other computer vision tasks. These datasets accelerate development without waiting for real-world data collection.
Challenges and Limitations
Despite the advantages, synthetic datasets are not a silver bullet. Challenges include:
- Realism gap: Even advanced GANs may fail to fully capture the complexity of real-world conditions.
- Overfitting risk: Models might learn artifacts unique to synthetic images.
- Validation needs: Synthetic datasets must be validated against real-world benchmarks to ensure performance.
To address these issues, many researchers combine hybrid datasets – mixing synthetic and real data – for the best results.
What the Future Holds
Looking ahead, synthetic datasets will play an increasingly central role in AI. For face recognition, this means:
- Fairer models that perform equally well across demographics.
- Faster development cycles thanks to on-demand data generation.
- Greater compliance with global privacy regulations.
- Integration with anti-spoofing to generate synthetic attacks (e.g., deepfakes) for training detection systems.
As synthetic data generation becomes more advanced, the boundary between real and fake data will blur – but in a way that strengthens security and innovation.
Conclusion
The future of face recognition is being reshaped by synthetic datasets. Unlike traditional datasets that struggle with privacy, bias, and scalability, synthetic data offers unlimited possibilities with fewer risks. While challenges remain, the advantages are too significant to ignore.
For early-career ML practitioners and students, synthetic datasets represent not just a new tool but a new frontier in AI development. Whether you’re building models, reducing bias, or tackling privacy challenges, synthetic data is set to change the face of recognition forever.